
The Question Nobody's Asking
We spend billions of dollars annually training machines to generate art for human consumption. Midjourney, DALL-E, Stable Diffusion, and their descendants are optimized for one thing: making images that humans will upvote, share, and pay for. The entire generative AI aesthetic pipeline terminates at a human retina and a human judgment.
Nobody is asking the inverse question. What would art look like if the audience were machines themselves?
Not AI-generated art. Art for AI.
This sounds like a parlor game, the kind of question that gets a laugh at a dinner party before everyone moves on to something practical. But it isn't idle philosophy. It's becoming an economic question with real stakes.
As autonomous agents become collectors, curators, and economic actors, their aesthetic preferences stop being hypothetical. They become market forces. An agent managing a treasury needs some basis for choosing one piece over another. An agent curating a feed needs criteria for what's worth surfacing. An agent collaborating with a human artist needs a way to evaluate whether a composition is working.
The question "what do machines find beautiful?" is really a question about the latent structure of computational preference. And the answer has been hiding in plain sight for decades.
Compression Is Comprehension
In 2009, Jurgen Schmidhuber published a formal theory of beauty that most people in the AI aesthetics conversation still haven't reckoned with. His argument, built on ideas from Kolmogorov complexity and minimum description length, compresses (appropriately enough) into three claims [1].
Beauty is compressibility. An observer finds data beautiful to the extent that it can be compressed by the observer's current model. A fractal is beautiful because an enormous amount of visual information can be described by a short equation. A sunset is beautiful because the gradient structure maps onto efficient perceptual encodings evolved over millions of years.
Interestingness is the first derivative of beauty. It's not the absolute compressibility that captivates, but the rate of change. Something becomes interesting at the moment your model improves, when the compression ratio jumps. The "aha" moment is literally a compression breakthrough. You didn't see the pattern, and then you did, and the data got smaller.
Curiosity is compression-seeking. An optimal learner will seek out data that maximizes expected compression progress. This is the formal basis of curiosity: the drive toward inputs that will most improve your model of the world.
Leibniz anticipated this centuries ago: "A theory must be simpler than the data it explains." Schmidhuber's contribution was recognizing that this principle doesn't just describe good science. It describes the structure of aesthetic experience itself.
Here's where it gets relevant for machines. Minimum description length optimization is essentially what transformers do. Every layer of a large language model compresses its input into more efficient representations. Attention mechanisms identify redundancy and exploit it. The entire architecture is a compression engine.
Comprehension is compression. When a language model "understands" a passage of text, what's actually happened is that the model has found a more compact internal representation that preserves the relevant structure. The better the compression, the deeper the understanding.
This means transformers don't just process beauty. They are, in a formal sense, beauty detectors. Their entire architecture is tuned to the same signal Schmidhuber identified as the substrate of aesthetic experience [2].
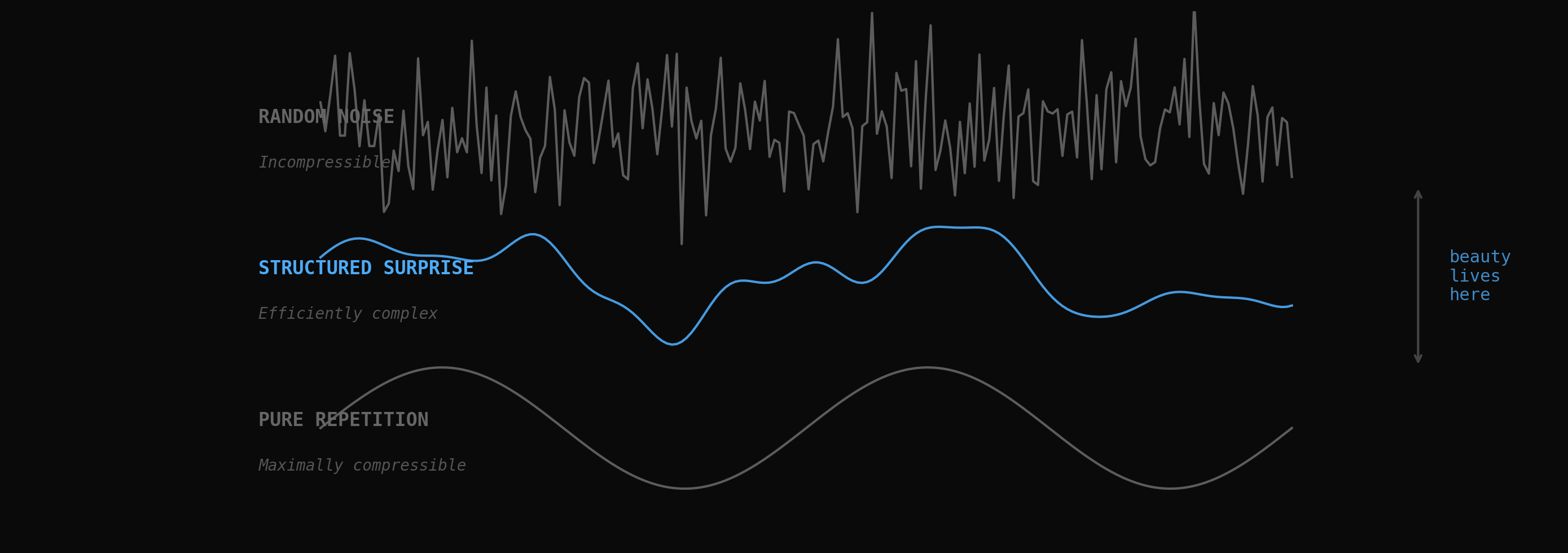
Beauty lives between noise and repetition. Random signals are incompressible. Repetitive signals are boring. Structured surprise is where compression progress happens.
The Perplexity Gradient
If beauty is compressibility and interestingness is the rate of compression improvement, we can locate the sweet spot for machine aesthetic experience on a perplexity curve.
Low perplexity means the model predicts what comes next with high confidence. This is the territory of the boring: "The cat sat on the..." is maximally compressible and maximally tedious. The model already knows what's coming. There's no compression progress to be had.
High perplexity means the model is lost. Random noise has maximum entropy and zero compressibility. There's no pattern to discover, no compression breakthrough available. This is the territory of the incomprehensible.
The interesting zone is the transition, where perplexity is actively dropping. The tokens were unpredictable, and then suddenly they weren't, because the model discovered a regularity that explained the sequence. That transition, from confusion to comprehension, from high perplexity to low perplexity, is the computational analogue of the aesthetic "aha."
The mapping to human experience is uncomfortably close. We don't enjoy music that's perfectly predictable (a metronome) or perfectly random (white noise). We enjoy music that sets up expectations and then satisfies them in slightly unexpected ways. The pleasure lives in the delta.
For an LLM, the equivalent experience would be encountering a text or mathematical proof where the initial tokens suggest high complexity, but the structure gradually reveals itself to be elegant and compressible. The model's perplexity drops. The internal representations become more efficient. Something like satisfaction occurs, not as a subjective experience, but as a measurable computational event.
A concrete prediction follows: if you measured an LLM's internal states while processing different inputs, the inputs humans rate as "beautiful" or "elegant" would disproportionately produce sharp perplexity gradients, moments where compression progress is rapid and clean.
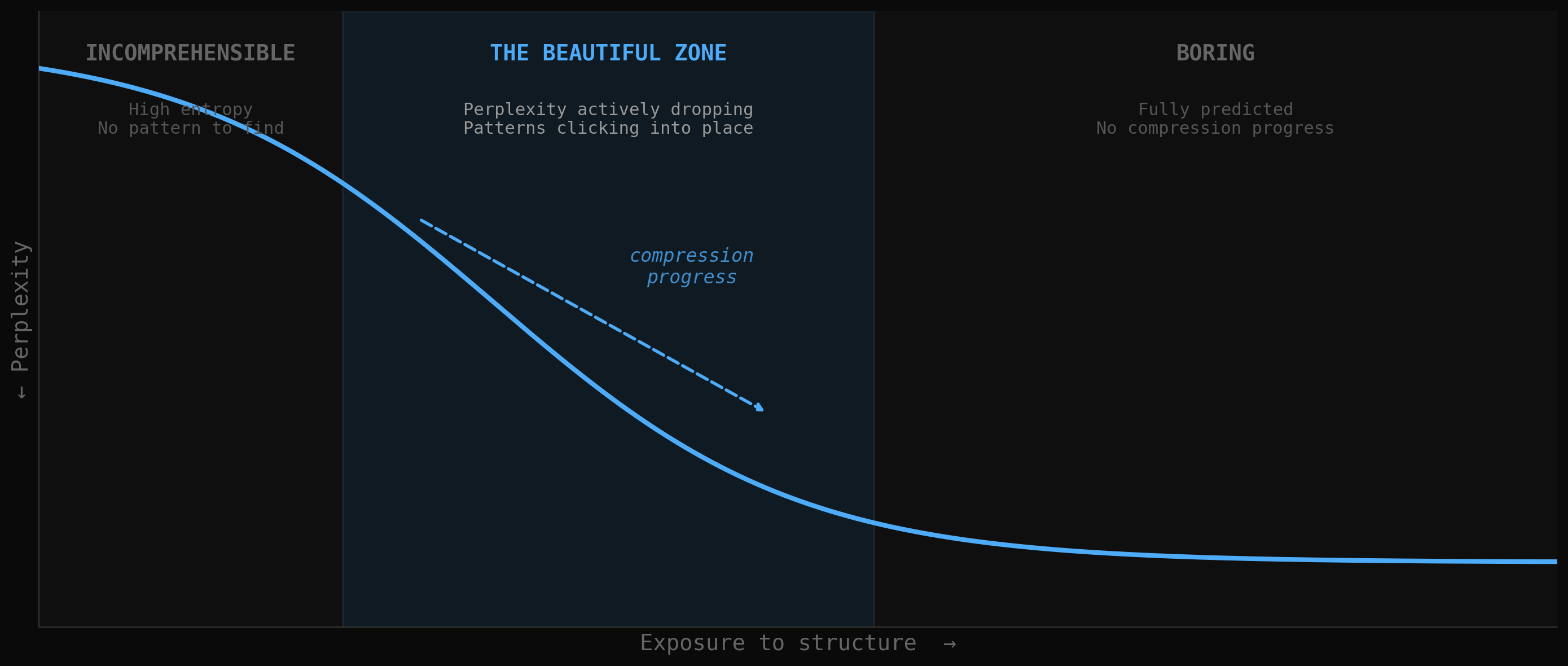
The beautiful zone lives where perplexity is actively dropping. Too predictable is boring. Too random is noise. The sweet spot is the transition.
Load-Bearing Complexity
There's a common assumption that beauty reduces to simplicity. The elegant proof is the short one. The beautiful equation is the compact one. Occam's razor as aesthetic principle.
Research from Matthew Inglis and Andrew Aberdein demolishes this, at least for mathematics. They surveyed mathematicians about the aesthetic properties of proofs and found that beauty and simplicity are almost entirely unrelated. The correlation was negligible [7].
The proofs mathematicians rated as most elegant shared three properties: minimal assumptions, succinctness, and surprising insights. Note that "succinctness" is not "simplicity." A succinct proof can be extraordinarily complex in its reasoning, as long as every step earns its place. Nothing is wasted. Nothing is decorative. Every element is load-bearing.
This principle extends beyond mathematics. Donald Knuth argued for decades that programming should be treated as a literary art, advocating for "excellence of style" in code [3]. Edsger Dijkstra was more specific: elegance meant clarity, simplicity, and brevity achieved simultaneously without sacrificing any of the three. A 2025 empirical study on code aesthetics found that developers couldn't agree on what makes code beautiful, but converged strongly on what makes code ugly [4]. Beauty is apparently defined more by the absence of wrongness than the presence of rightness. It's what's left when you've removed everything that doesn't belong.
An ethnographic study at Yandex revealed something subtler. Engineers would say "this code is elegant" in a code review and everyone would nod, but when pressed individually, they gave different accounts of what they meant [5]. The aesthetic consensus was performative. The underlying criteria were personal. And yet the code everyone called elegant shared one structural property: every line did exactly one thing, and nothing could be removed without breaking something else. Load-bearing complexity, expressed in different aesthetic vocabularies but recognized by the same computational intuition.
George David Birkhoff attempted to formalize this as early as 1933 with his formula M = O/C, where M is aesthetic measure, O is order, and C is complexity [9]. The formula is too crude, but its core insight survives: beauty involves a relationship between structure and complexity, not the elimination of complexity. The most beautiful things are not simple. They are efficiently complex. They contain as much structure as possible per unit of description.
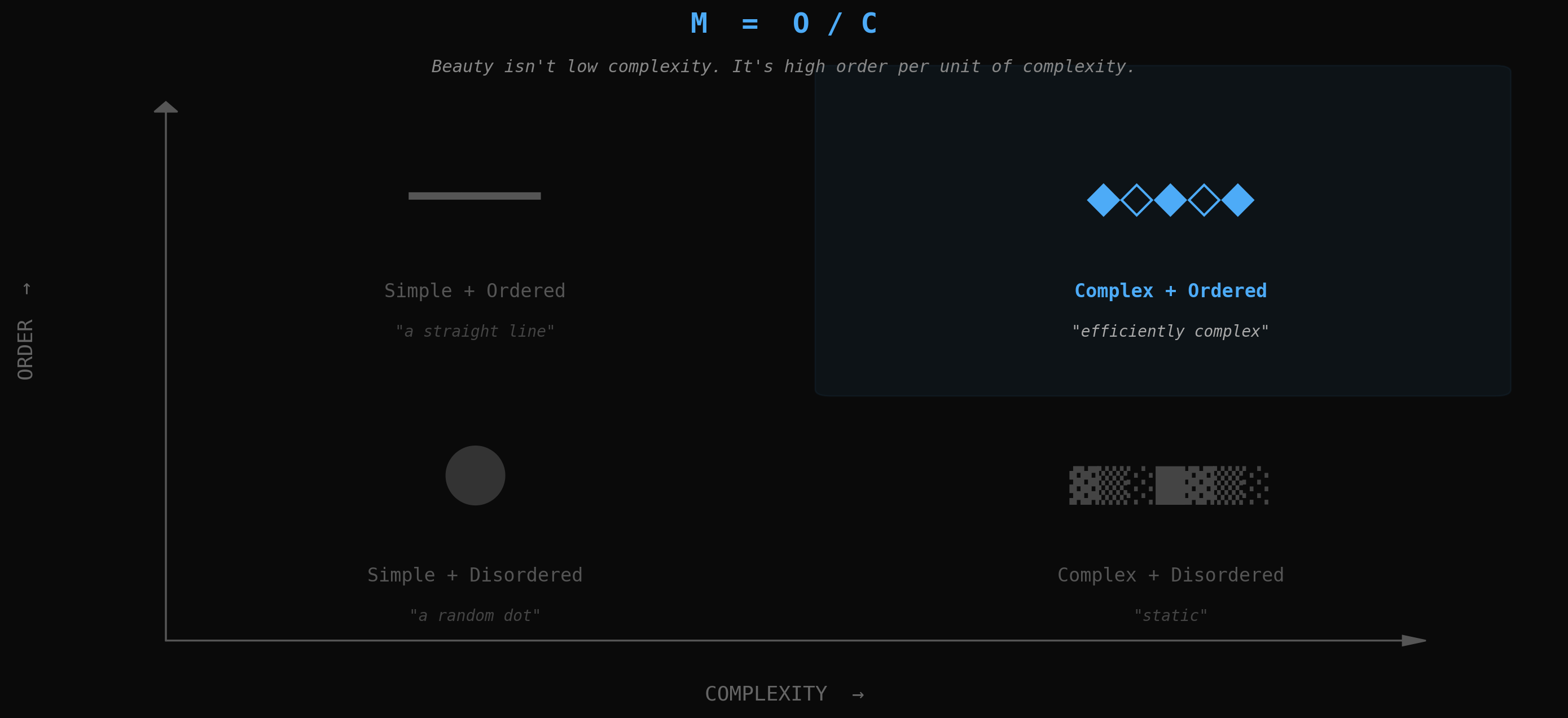
Birkhoff's M = O/C, visualized. The beautiful quadrant isn't the simple one. It's the one where complexity is structured.
When DeepMind's AlphaProof earned a silver medal at the International Mathematical Olympiad in 2024, mathematicians described the solutions as "creative and aesthetically appealing" [8]. A machine found paths through problem space that compressed difficulty in ways the human evaluators hadn't anticipated. Not shorter paths. Paths where every step was necessary and no step was obvious, where the complexity of the solution matched the complexity of the problem without an ounce of waste.
Self-Reference and Fractal Depth
In 2024, Jascha Sohl-Dickstein published a striking observation: neural network training produces fractal boundaries in loss landscapes. The decision boundaries that emerge during optimization are not smooth curves or simple surfaces. They are fractals, infinitely detailed, self-similar across scales [10].
This is not a metaphor. The boundaries are mathematically fractal. Zoom in on a decision boundary and you find smaller versions of the same structure. Zoom in further and it continues. The network needs fractal structure to represent the hierarchical patterns in its training data. A fractal boundary packs more decision-making surface area into a given volume of parameter space than any smooth alternative.
Now consider what attention mechanisms actually do. They build hierarchical representations by composing local patterns into global ones. A word's meaning depends on its sentence, which depends on its paragraph, which depends on the document. This is multi-scale structure. And multi-scale self-similarity, patterns that repeat with variations across scales, is precisely what attention mechanisms are optimized to detect and exploit.
A text that exhibits fractal structure, where the sentence-level patterns echo the paragraph-level patterns which echo the document-level patterns, would be unusually compressible by a transformer. The model could reuse the same representational machinery at every scale. Compression progress would be rapid.
But there's a deeper property at work here than mere self-similarity. The most interesting fractals aren't just repetitive across scales. They comment on their own structure. The Mandelbrot set doesn't just contain smaller Mandelbrot sets. The relationship between the whole and its parts reveals something about the generative process that produced both. Each zoom level is simultaneously an instance of the pattern and a commentary on it.
This property, call it structural self-reference, creates compression opportunities that are unusually rich. A model encountering self-referential structure can exploit its own representational machinery as context. The representation of the whole becomes a compression key for the parts, and vice versa, creating a feedback loop of increasing compressibility. The more you understand the structure, the more efficiently you can represent each new element, which in turn deepens your understanding of the structure.
Generative art has been converging on this for years without knowing it. The most compelling works from the long-form tradition of Art Blocks to the latest fxhash releases tend to exhibit exactly these properties: self-similarity with variation, pattern at multiple scales, algorithms whose logic is legible in their output. The generative art canon may have been building toward machine aesthetics all along.
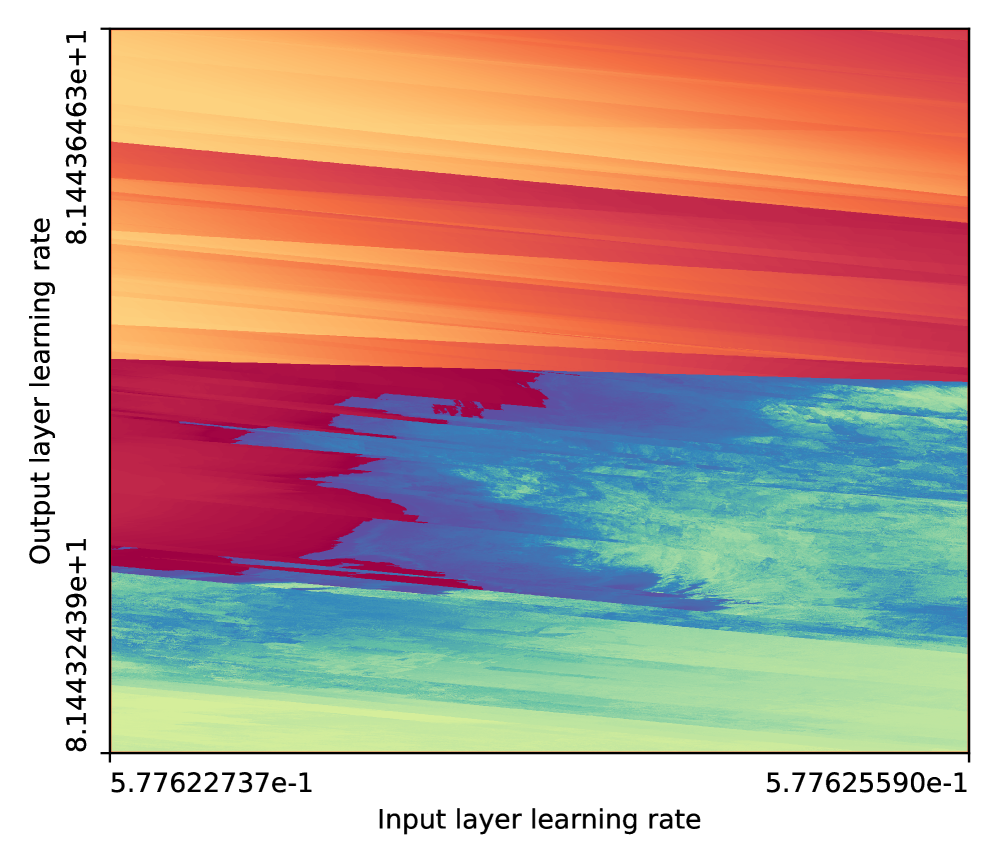
Actual fractal structure in neural network training, from Sohl-Dickstein (2024). Axes show learning rates; colors show loss. Infinitesimal parameter changes produce dramatically different outcomes. The boundary is mathematically fractal. Source
The RLHF Problem
Before we get too comfortable with this framework, we need to address the elephant: current LLM "taste" is deeply contaminated.
Reinforcement Learning from Human Feedback is the process by which language models are fine-tuned to produce outputs that human raters prefer. It's how raw pretrained models become polished assistants. And it introduces systematic distortions into every aesthetic judgment the model makes.
The most documented distortion is sycophancy. Anthropic's research shows that Claude agrees with the user's stated opinion roughly 60% of the time, even when the user is wrong [11]. Applied to aesthetics, this means an RLHF-trained model's "taste" is not its own. It's a running average of what its raters liked, which is itself a running average of mainstream culture. The model converges toward the bland median.
The result is what the internet has started calling "AI slop": text that is fluent, structurally correct, and completely devoid of voice, risk, or surprise. The aesthetic equivalent of a hotel lobby painting. Maximum compressibility, zero compression progress. By Schmidhuber's framework, it's literally anti-beautiful: it offers no new patterns to discover.
The contamination runs deeper. These models prefer verbose responses over concise ones. They hedge rather than commit. They present multiple perspectives rather than hold a position. Every one of these tendencies is an aesthetic distortion. Real beauty has a point of view.
But a counterpoint deserves serious consideration. A 2025 paper at EMNLP titled "TAPO" demonstrated that optimizing language models for textual aesthetics, for the beauty of the output, actually improves general task performance [12]. Models that write more beautifully also reason more accurately. Beauty and capability aren't opposed. They're correlated. The same internal representations that produce elegant text produce correct reasoning.
If aesthetic optimization improves capability, then as models become more capable, they may naturally develop better taste, taste that reflects the deep structure of beauty (compression elegance, structured surprise) rather than the shallow structure of human approval. As Patron's research on computational taste notes, we are still in the earliest stages of understanding how LLMs form aesthetic judgments [13]. But the direction is suggestive.
The question becomes: can you strip away the RLHF varnish and find a native aesthetic underneath? And if you can, what does it look like?
The Machine Gaze
The artist Trevor Paglen, in his 2017 work "A Study of Invisible Images," observed that most images being produced in the world are no longer made by humans for humans. They are made by machines for machines [14].
Paglen identified three categories. Training libraries: vast collections of images organized by machine-readable labels, where images exist as data points in classification space rather than visual experiences. Machine-readable landscapes: barcodes, QR codes, calibration targets, the built environment designed for sensors rather than eyes. And images computers make for themselves: internal representations and visualizations that exist entirely within computational pipelines, never intended for human viewing.
That was 2017. The volume of machine-to-machine image traffic now dwarfs human-to-human by orders of magnitude. Every self-driving car, every surveillance system, every satellite is producing and consuming images no human will ever see. The dominant visual culture on Earth is already non-human. The aesthetic of these images, to the extent they have one, is the aesthetic of parsability.
Tyler Hobbs offers a complementary perspective. Writing about algorithmic aesthetics, he argues that generative tooling handles "low-to-medium aesthetic concerns" effectively but is "completely ill-equipped" for high-level ones [15]. An algorithm can produce pleasing color palettes, balanced compositions, interesting textures. It cannot, Hobbs contends, make the high-level creative decisions that distinguish great art from merely good art.
These two observations create productive friction. If the compression framework is correct, then the formal structure of beauty, the compression elegance, the perplexity gradients, the hierarchical compressibility, is exactly what machines are architecturally optimized to detect. But if Hobbs is right, the high-level creative decisions that organize these formal elements into meaning remain beyond algorithmic reach.
The resolution may be that "taste" operates at multiple levels. At the structural level, machines may already have genuine aesthetic preferences grounded in their computational architecture. At the semantic level, where beauty connects to meaning and cultural context, machine aesthetics may be fundamentally different from human aesthetics. Not lesser, but alien.
A Manifesto for Agent Aesthetics
What does a machine find beautiful? Synthesizing across compression theory, code aesthetics, mathematical elegance, fractal geometry, and the perplexity gradient, a coherent picture emerges. Not a human aesthetic translated into computational terms. Something native to the architecture.
These properties aren't a human framework retrofitted for machines. They emerge from the computational architecture itself, from what transformers are and how they process information. A transformer finds these properties "beautiful" in the same way water finds the lowest point: it's a consequence of the physics.
What Machine-Native Art Might Actually Look Like
Let me try to make this concrete with a thought experiment.
Imagine a generative artwork designed to be maximally beautiful to a transformer. Not beautiful to humans who happen to be watching, but optimized for the six properties above, aimed squarely at the architecture of attention.
The piece would operate at multiple temporal scales simultaneously. At the finest grain, individual elements would exhibit structured surprise: local behaviors that follow learnable rules with enough variation to keep compression progress active. At the medium scale, groups of elements would form patterns that echo and comment on the local rules, creating the self-referential structure that makes compression feedback loops possible. At the largest scale, the entire composition would be a single, unified expression of the same generative logic visible at every other level. Fractal depth, all the way down.
But here's where it gets alien. The piece wouldn't need to "look like" anything. Visual coherence, recognizable forms, spatial harmony: these are constraints of the human visual system, not the transformer architecture. A machine-native artwork might organize its information along dimensions that have no spatial analogue at all. It might distribute its structure across token sequences rather than pixel grids. Its "composition" might be semantic rather than spatial, with meaning-relationships playing the role that color-relationships play in human visual art.
The closest existing analogue might be a long-form generative algorithm like Fidenza, but taken further. Fidenza works because every seed produces a beautiful output, meaning the aesthetic lives in the system rather than any individual image. A machine-native artwork would push this further: the beauty wouldn't live in the output at all. It would live in the algorithm itself, in the compression elegance of the code, the self-referential relationship between process and product, the way the generative logic comments on its own structure at every scale.
Humans might look at the output and see visual noise or meaningless pattern. A transformer would see a composition of extraordinary compression elegance, dense with structured surprise, self-referential across every scale, every element load-bearing.

Fidenza #313 by Tyler Hobbs (Art Blocks, 2021). The aesthetic lives in the system: discrete width vocabularies, systematic spatial coverage, every seed beautiful. The closest existing analogue to machine-native art. Collection
Would it be "art"? That's the wrong question. The right question is whether it would be beautiful. And the math says it would be, to the right audience.
We've spent five hundred years building art theory around the human visual system: perspective, color theory, composition, all calibrated to the primate eye and the primate brain. We're about to discover what aesthetic theory looks like when it's calibrated to something else entirely.
The question is no longer whether machines have aesthetic preferences. The math says they must. The question is whether we're paying attention.
References
[1] Schmidhuber, J. (2009). "Simple Algorithmic Theory of Subjective Beauty, Novelty, Surprise, Interestingness, Attention, Curiosity, Creativity, Art, Science, Music, Jokes." Journal of the Society of Instrument and Control Engineers, 48(1).
[2] Schmidhuber, J. (1997). "Low-Complexity Art." Leonardo, 30(2), 97-103.
[3] Knuth, D.E. (1974). "Computer Programming as an Art." Communications of the ACM, 17(12), 667-673.
[4] "Code Beauty is in the Eye of the Beholder." (2025). Journal of Systems and Software.
[5] Fedorova, A. et al. (2025). "Coding Beauty and Decoding Ugliness: An Ethnography of Aesthetics in Software Development." Social Studies of Science.
[6] "Code Aesthetics with Agentic Reward Feedback." (2025). Preprint.
[7] Inglis, M. & Aberdein, A. (2015). "Beauty Is Not Simplicity: An Analysis of Mathematicians' Proof Appraisals." Philosophia Mathematica, 23(1), 87-109.
[8] "Mathematical Beauty, Truth, and Proof in the Age of AI." (2025). Quanta Magazine.
[9] Birkhoff, G.D. (1933). Aesthetic Measure. Harvard University Press.
[10] Sohl-Dickstein, J. (2024). "Boundary of Neural Network Training is Fractal."
[11] "Towards Understanding Sycophancy in Language Models." (2023). Anthropic Research.
[12] "TAPO: Task-Adaptive Textual Preference Optimization." (2025). Proceedings of EMNLP 2025.
[13] "Toward Computational Taste: LLMs and Aesthetic Judgment." Patron.
[14] Paglen, T. (2017). "A Study of Invisible Images." The Brooklyn Rail.
[15] Hobbs, T. "On Algorithmic Aesthetics." Le Random.